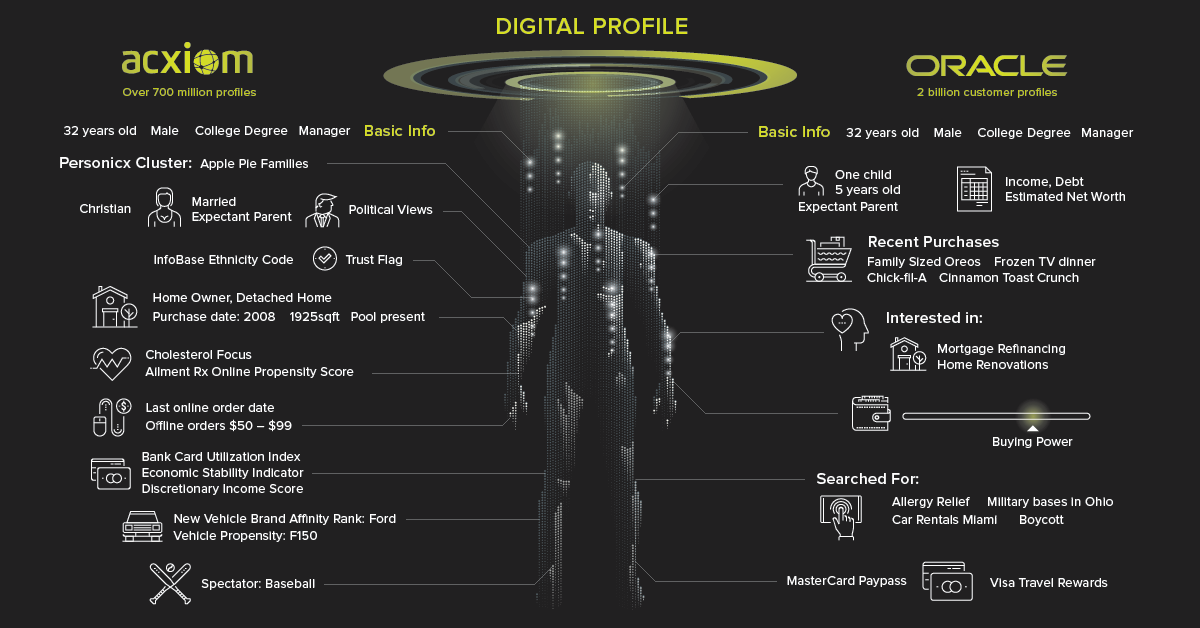
Here on dry land, the massive volume of content and meta data we produce fuels a marketing research industry that is worth nearly $50 billion. Every instant message, page click, and step you take now produces a data point that can be used to build a detailed profile of who you are.
Every breath you take, Every move you make
The coarse-grained demographics and contact information of yesteryear seems quaint compared to today’s sophisticated data collection battleground. In the past, marketers would make judgement calls on your likely income and family structure based on where you lived, and you’d receive “targeted” mail and calls from telemarketers. Loyalty programs and the emergence of web analytics pushed things a little further. Today, the steady march of technological advancement has created a vast data collection empire that measures every aspect of your digital life and, increasingly, your offline life as well. Facebook alone uses nearly one hundred data points to target ads to you – everything from your marital status to whether you’ve been on vacation lately or not. Telecoms have access to extremely detailed information on your location. Apple has biometric data. Also watching your every move are web trackers. “Cookie-syncing” is one of the sneaky ways advertisers can follow you around the internet. Basically, cookie-syncing allows third parties to share browsing information at such a large scale that even the NSA “piggybacks” off them for surveillance purposes.
Following the ones and zeros
While web trackers and companies like Apple and Google are collecting a lot of personal and behavioral data, it’s the whales of the data ecosystem – data brokers – who are creating increasingly detailed profiles on almost everyone. – Senator Al Franken (D-Minn) The goal of data brokers, such as Experian or Acxiom, is to siphon up as much personal data as possible and apply it to profiles. This data comes from a wide variety of sources. Your purchases, financial history, internet activity, and even psychographic attributes are mixed with information from public records to create a robust dossier. Digital profiles are then sorted into one of thousands of categories to help optimize advertising efforts.
Fear the shadow profile?
According to Pew Research, 91% of Americans “agree” or “strongly agree” that people have lost control over how personal information is collected and used. Though optimizing clickthroughs is a big business, companies are increasingly moving beyond advertising to extract value from their growing data pipeline. Amalgamated data is increasingly being viewed as a clever way to assess risk in the decision-making process (e.g. hiring, insurance, loan or housing applications), and the stakes for consumers are going up in the process. For example, a man may feel comfortable sharing their HIV status on Grindr (for practical reasons), but may not want that information going to a third party. (Unfortunately, that really happened.) In 2015, Facebook filed a patent for a service that would help insurance companies vet people based on the credit ratings of their social network.
The More You Know
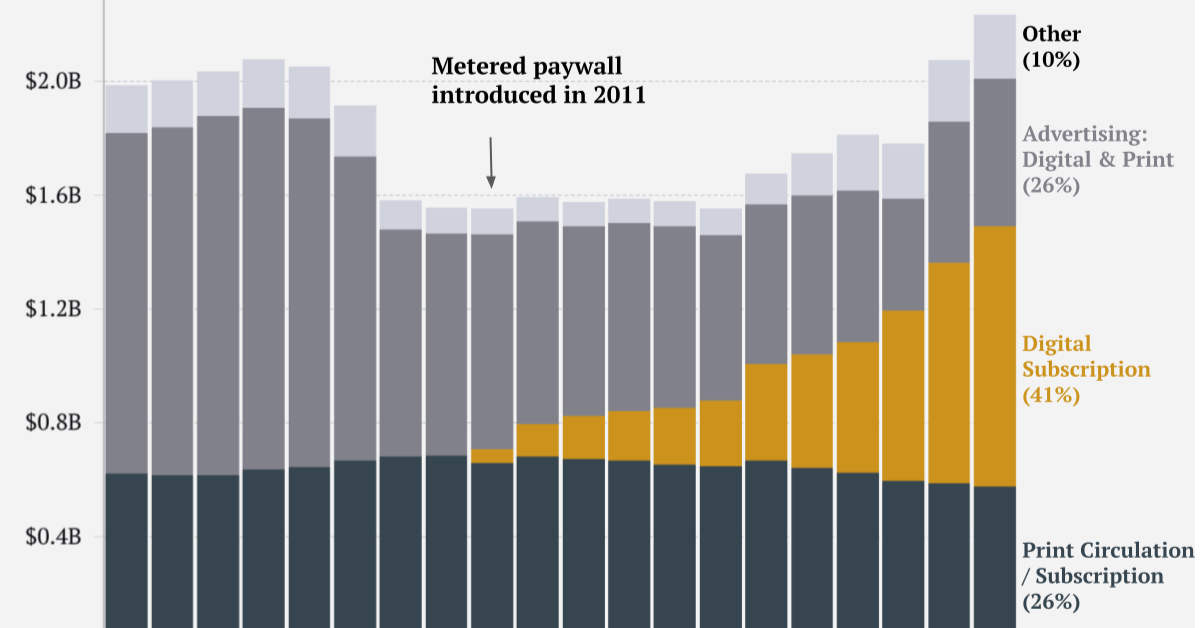
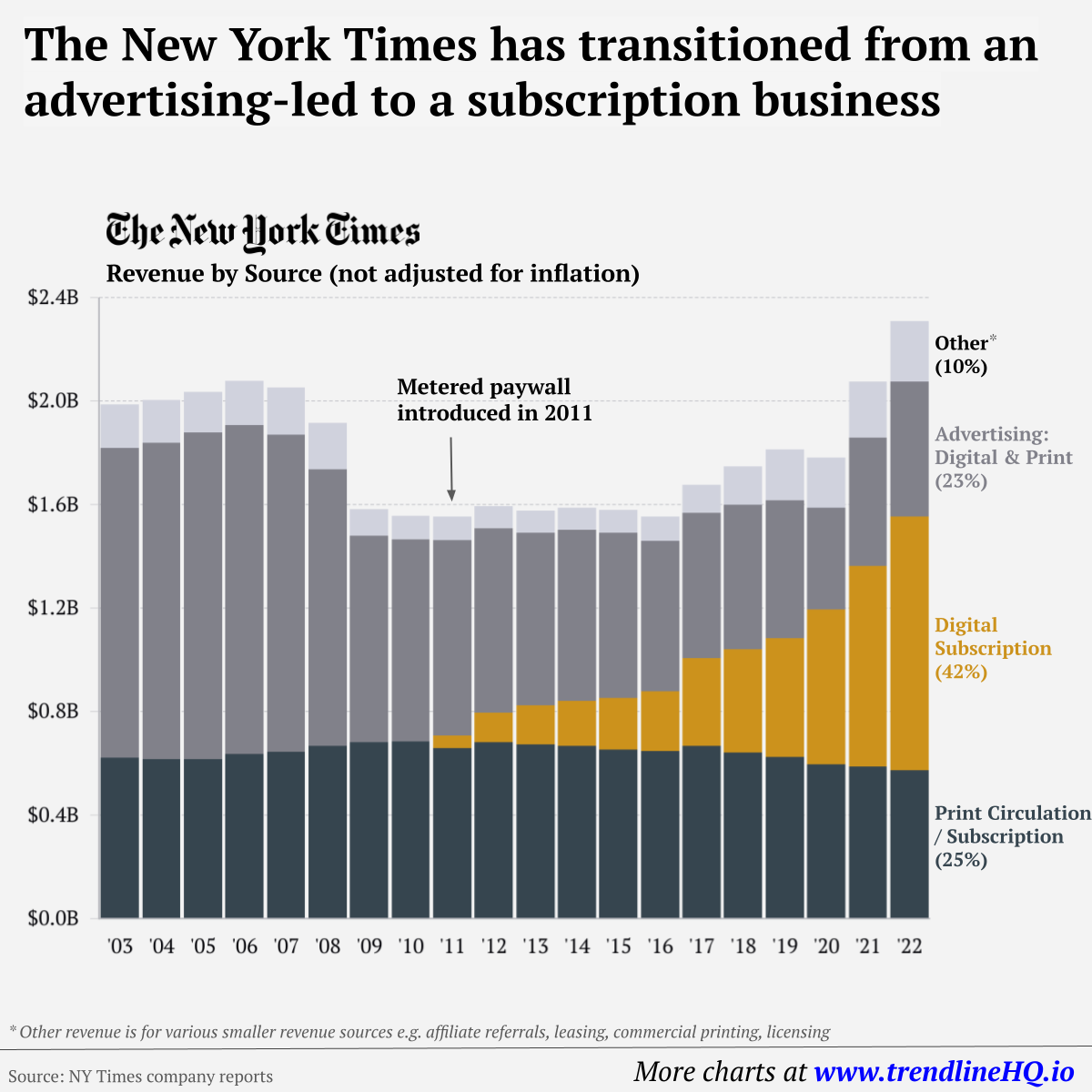
Below the surface of our screens, our digital profiles continue to take shape. Measures like adjusting website privacy controls and clearing cookies are a good start, but that’s only a fraction of the data companies are collecting. Not only do data brokers make it hard to officially opt out, their partnerships with corporations and advanced data collection methods cast such a wide net, that it’s almost impossible to exclude individual people. Data brokers have operated with very little scrutiny or oversight, but that may be changing. Under intense public and governmental pressure, Facebook recently cut ties with data brokers. For a company that has bullishly pursued monetization of user data at every turn, the move is a sign that the public sentiment is changing. The more information on the personal data industry, visit Cracked Labs’ report on the issue. on Similar to the the precedent set by the music industry, many news outlets have also been figuring out how to transition into a paid digital monetization model. Over the past decade or so, The New York Times (NY Times)—one of the world’s most iconic and widely read news organizations—has been transforming its revenue model to fit this trend. This chart from creator Trendline uses annual reports from the The New York Times Company to visualize how this seemingly simple transition helped the organization adapt to the digital era.
The New York Times’ Revenue Transition
The NY Times has always been one of the world’s most-widely circulated papers. Before the launch of its digital subscription model, it earned half its revenue from print and online advertisements. The rest of its income came in through circulation and other avenues including licensing, referrals, commercial printing, events, and so on. But after annual revenues dropped by more than $500 million from 2006 to 2010, something had to change. In 2011, the NY Times launched its new digital subscription model and put some of its online articles behind a paywall. It bet that consumers would be willing to pay for quality content. And while it faced a rocky start, with revenue through print circulation and advertising slowly dwindling and some consumers frustrated that once-available content was now paywalled, its income through digital subscriptions began to climb. After digital subscription revenues first launched in 2011, they totaled to $47 million of revenue in their first year. By 2022 they had climbed to $979 million and accounted for 42% of total revenue.
Why Are Readers Paying for News?
More than half of U.S. adults subscribe to the news in some format. That (perhaps surprisingly) includes around four out of 10 adults under the age of 35. One of the main reasons cited for this was the consistency of publications in covering a variety of news topics. And given the NY Times’ popularity, it’s no surprise that it recently ranked as the most popular news subscription.